
Gravity Spy Machine Learning by Machine Learning
Machine learning offers powerful tools for performing complex tasks – its applications are broad in scope, and virtually limitless given sufficient resources. Within Gravity Spy, armed with the ever-growing dataset of detector glitches classified by our volunteers, we are able to construct an algorithm that can not only identify glitches in detector data, but distinguish between different glitch types with impressive accuracy. ChatGPT is another application of machine learning that has been hitting the headlines recently. It is notable in being able to write detailed text in response to prompts. To illustrate its potential, I asked to summarise the inner workings of the Gravity Spy machine learning classifier. Its response is below, unedited (except for some visual aids I have provided)…
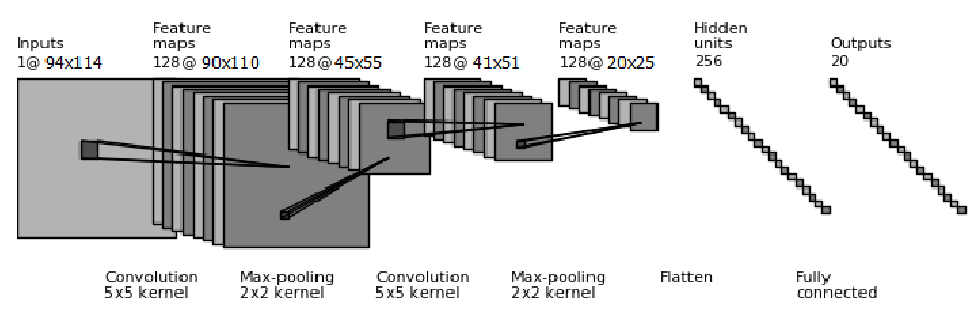
At the heart of the Gravity Spy project is a machine learning algorithm called a convolutional neural network (CNN). CNNs are a type of deep learning algorithm that are particularly effective at image recognition tasks. CNNs are particularly well-suited to analysing complex data such as the spectrograms produced by gravitational wave detectors. These spectrograms represent the frequency and intensity of the detector output over time, and can be thought of as a two-dimensional image.
The Gravity Spy CNN consists of multiple layers, each designed to extract increasingly complex features from these input spectrograms. The first layers are convolutional layers, which apply a set of learned filters to the input image. These filters are designed to highlight specific features in the image, such as lines, edges, or curves. The convolution operation involves sliding the filters over the input data, multiplying the values at each location, and summing the results.
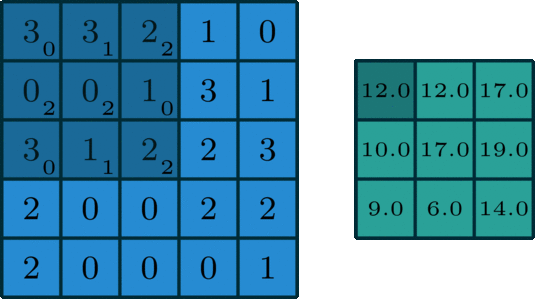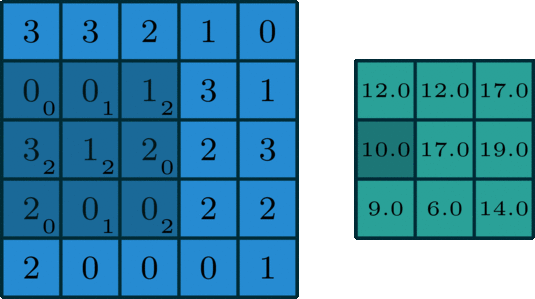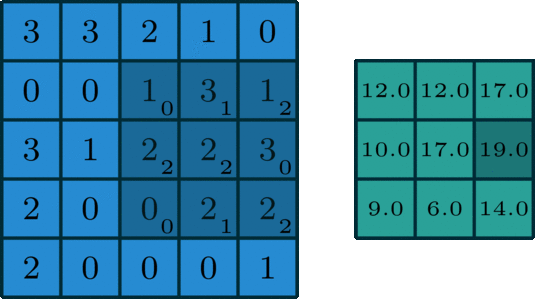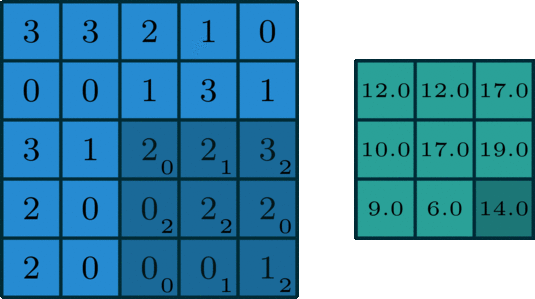
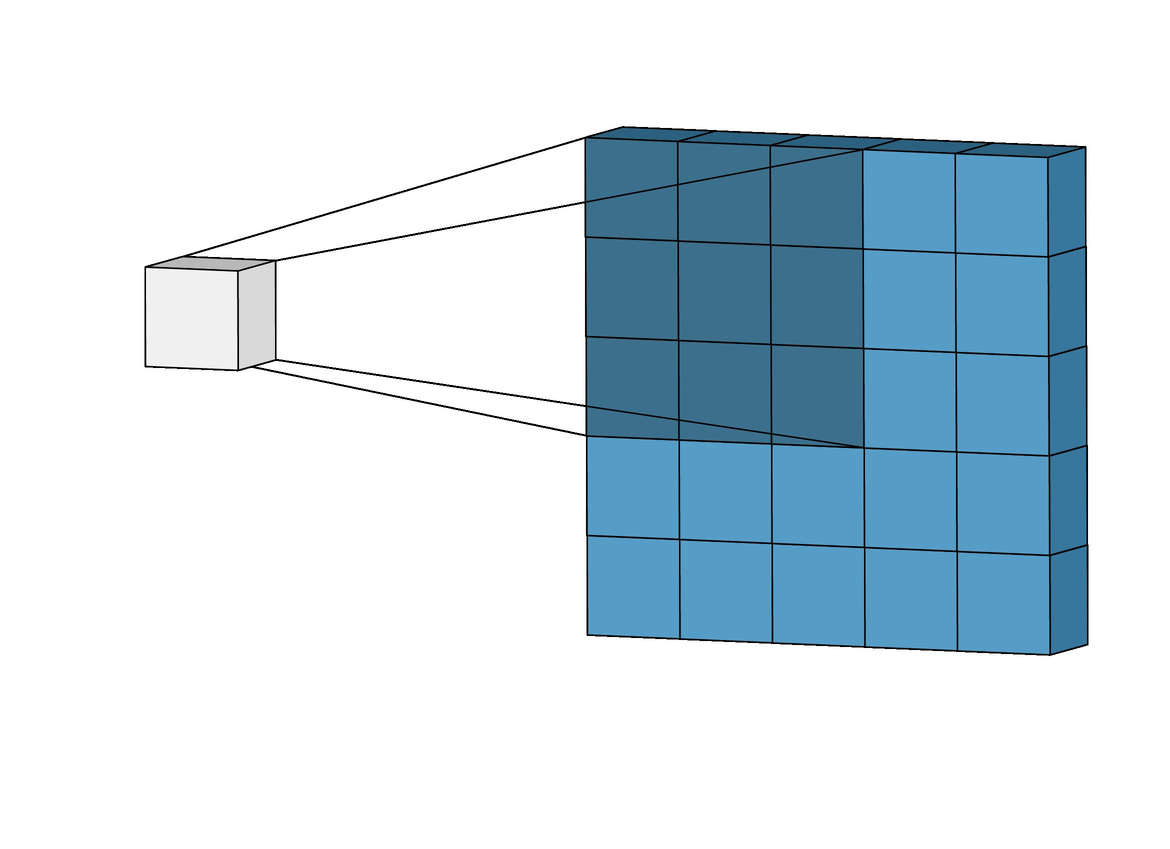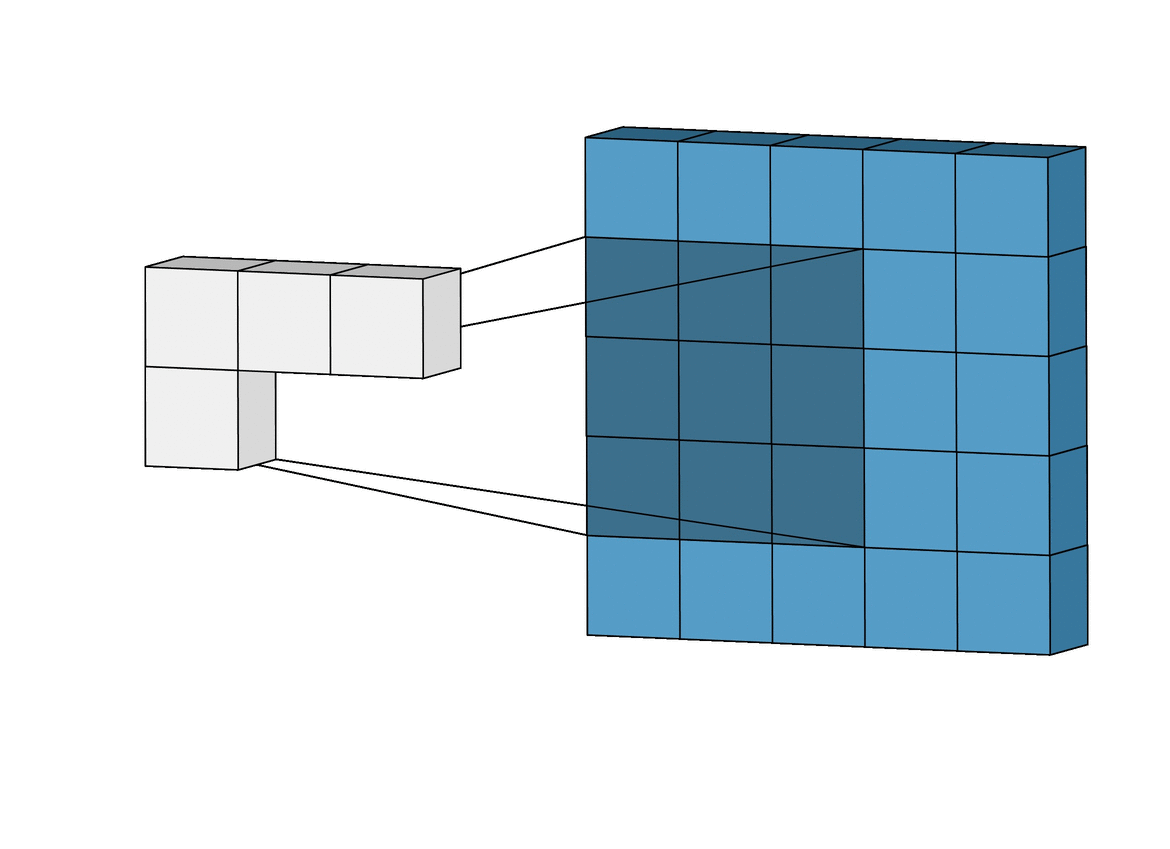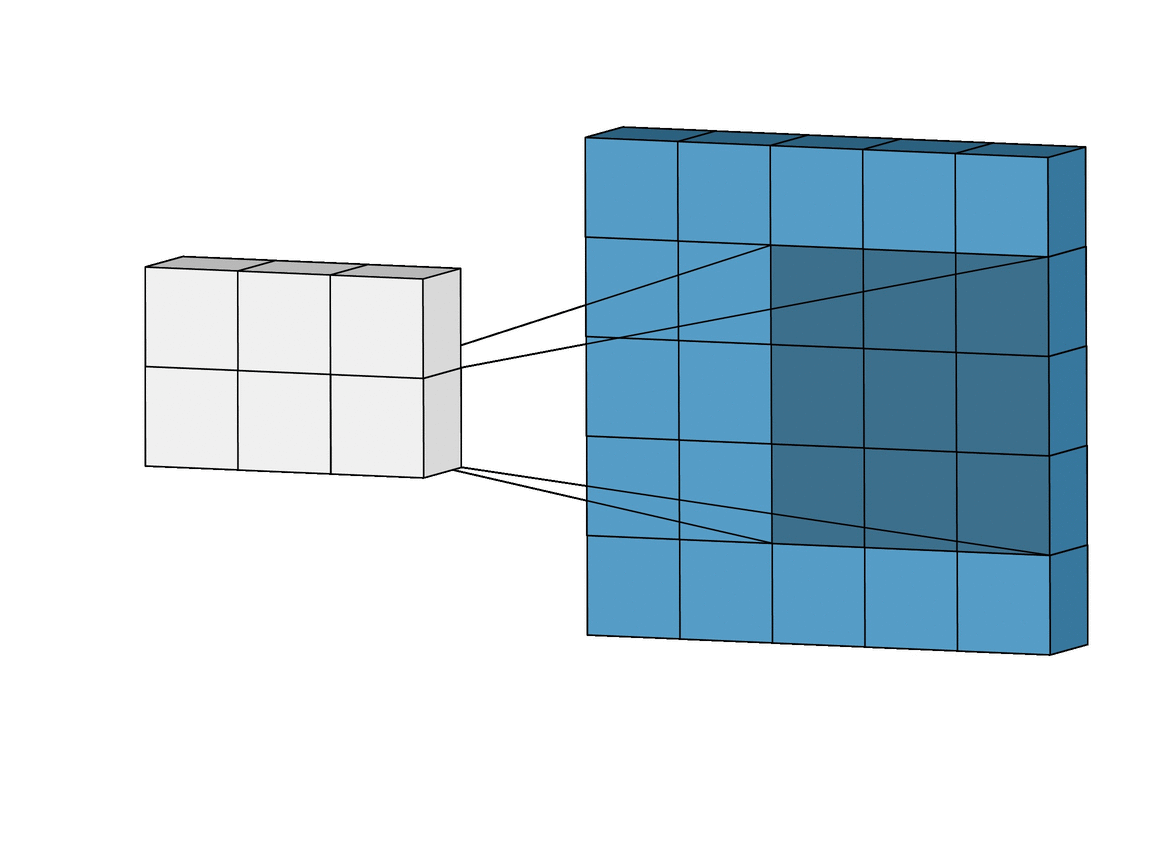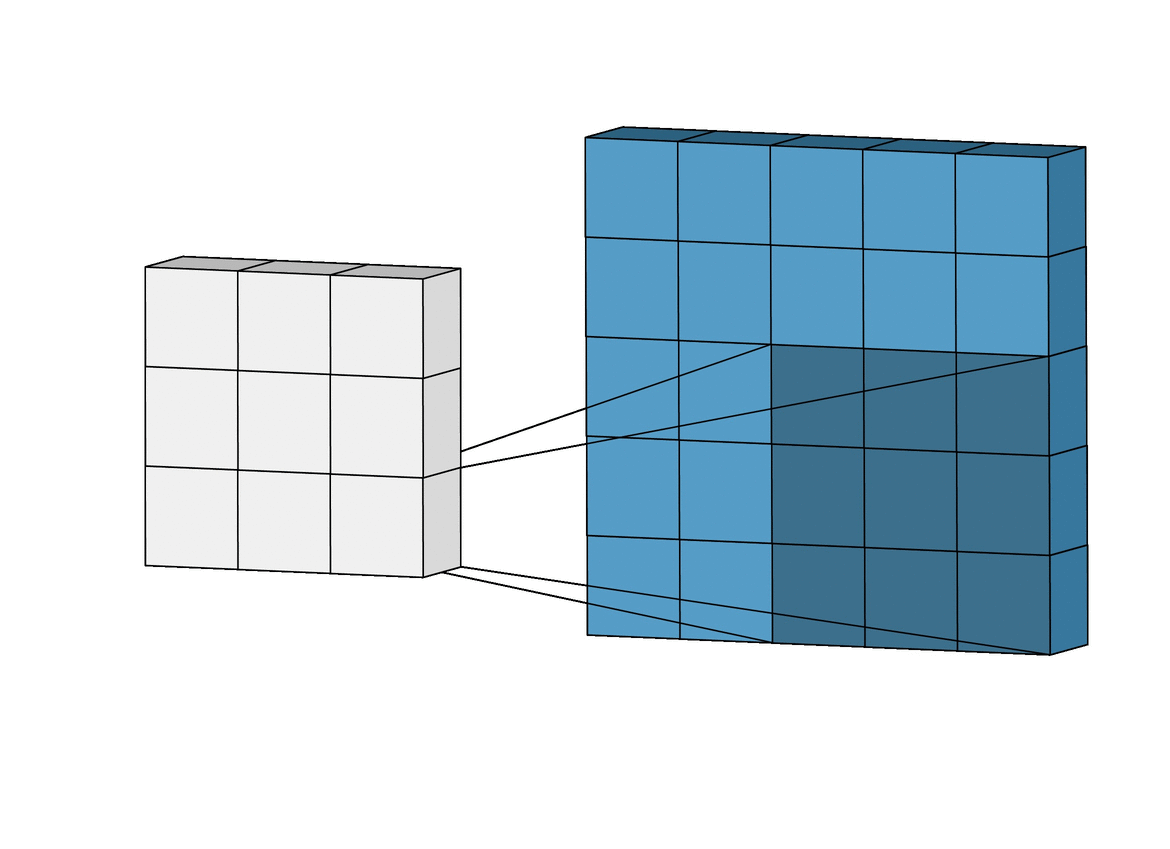
The output of the convolutional layers is passed through max-pooling layers, which downsample the output by selecting the maximum value in each neighbourhood. This reduces the dimensionality of the output, making the model more efficient while preserving the most important features. This process is repeated with multiple filters to generate a set of feature maps for each layer of the network. Finally, the output from the last convolutional and pooling layers is flattened and fed into one or more fully connected layers, which produce the output glitch classification. These layers use weights to connect every neuron in one layer to every neuron in the next layer, allowing the network to learn complex relationships between the extracted features and the corresponding glitch that they were derived from.
To train the Gravity Spy CNN, a large dataset of labelled examples is required. Citizen scientists contribute to this effort by classifying glitches on Zooniverse. The CNN is trained using an optimization algorithm to minimize a loss function, with the cross-entropy loss function being used in the case of Gravity Spy. Cross-entropy is a measure of the difference between the predicted probabilities and the true labels for each example in the training set. By minimizing the cross-entropy loss, the CNN is able to learn to make increasingly accurate predictions about which glitch class each spectrogram belongs to. This minimisation is achieved by finely tuning the parameters of each layer of the CNN in an iterative fashion.
One of the key contributions of the Gravity Spy project has been the identification of new classes of glitch. These include the Crown (also known as Fast Scattering), Pizzicato, Paired Doves, and Helix classes. Paired Dove and Helix classes were identified during early beta testing of Gravity Spy on Zooniverse, while Crown was particularly common during the third observing run of LIGO. Pizzicato, which looks like a UFO in spectrograms, was recently identified, and is thought to be related to violin modes in the LIGO detector’s suspension system. The Gravity Spy CNN can easily incorporate these new glitch classes, and by properly sub-dividing existing glitch classes into new ones their origins in the detectors can be better identified.
In conclusion, the Gravity Spy project is an excellent example of the power of citizen science and machine learning in advancing our understanding of the universe. By harnessing the collective intelligence of volunteers on Zooniverse and using a CNN trained on a large dataset of labelled examples, the project has made it possible to distinguish true gravitational wave signals from noise and identify new classes of glitch. As machine learning technology continues to improve, we can expect to see similar projects emerging in other areas of science, enabling us to tackle ever more complex and challenging questions.
Impressive (and perhaps a little unnerving)! ChatGPT knew a lot about Gravity Spy and convolutional neural networks by default. It did need to be told about the new glitch classes, and the specifics of the layers used in our network, but once told, it was able to write about them, as you can see! I didn’t tell it to say that Gravity Spy is excellent.
The key to ChatGPT’s remarkable abilities is the vast high-quality training dataset provided to it. Without this dataset, it would not be possible to produce such powerful generative algorithms. In a similar vein, the Gravity Spy classifier’s incredible capability to classify glitches in gravitational wave detector data is only possible because of the high-quality dataset of labelled glitch classifications it is provided: the work of our volunteers!
- Christian Chapman-Bird, on behalf of the Gravity Spy team.
Research Spotlight: Recent Gravitational-Wave Glitch Studies
We’re learning more about glitches in gravitational wave detectors all the time. The most recent LIGO–Virgo–KAGRA Collaboration meeting (12–16 September 2022) in Cardiff featured the latest progress on our detectors and data analysis. Many research projects were presented as posters: several were looking at topics related to glitches, and many used results from the Gravity Spy project for some part of their work! We’ve reached out to authors of these posters to spotlight their work in this blog post. Below you’ll find brief summaries about these research projects, and a glimpse into some of the science that contributing to Gravity Spy can enable.
Investigations of Increased Detector Noise due to Trains at LIGO Livingston – Jane Glanzer (LSU)
Scattered light is one of several types of noise sources present in the LIGO detectors. Specifically, Fast Scattering (known as Crown in Gravity Spy) is a type of scattering that occurs with increased ground motion in the 1-6 Hz (anthropogenic) and 0.1–0.3 Hz (microseism) band. Its structure takes the form of small arches present in time frequency space.
Scattering happens when light from the main laser path is scattered by a mirror reflected by another surface. A fraction of this scattered light can rejoin the main path, and introduce noise back into the main gravitational wave data channel. Environmental seismic disturbances contribute to the production of scattered light and limited detector sensitivity.
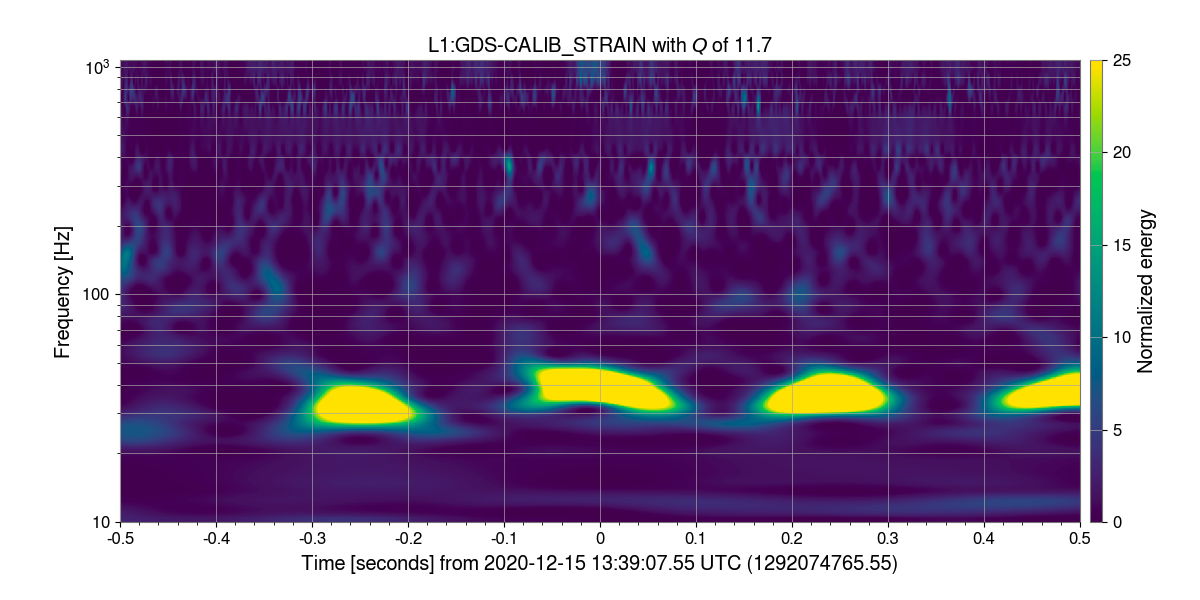
Trains near the LIGO Livingston detector are one of the main causes for increased seismic motion. Through the use of the linear regression tool LASSO, we searched for narrow band seismic frequencies to determine possible detector couplings responsible for these fast scattering glitches. This is done by looking for correlations between increases in ground motion and the calibrated strain data. The results find that the most common seismic frequencies that correlate with increases in detector noise are 0.6–0.8 Hz, 1.7–1.9 Hz, 1.8–2.0 Hz, and 2.3–2.5 Hz. In the Livingston detector, the arm cavity baffles and cryobaffles have resonances such that they may be the culprits for some of the Fast Scattering seen in O3 due to the train motion.
ArchEnemy: Subtracting scattered light artefacts from gravitational-wave data – Arthur Tolley (Portsmouth)
While the LVK have observed ~90 gravitational-wave signals to date, searching for these signals in the gravitational-wave strain data isn’t easy! This is made more complicated by the presence of random bursts of noise, known as glitches, in the data.
A very common glitch seen in the third observing run is caused by the scattering of light within the gravitational-wave detectors, colloquially called Scattered Light. I have been developing the ArchEnemy pipeline which can find these glitches and remove them from gravitational-wave data. We model scattered light glitches and produce a template bank of scattered light templates to matched filter with gravitational-wave data, allowing us to identify these glitches in a manner similar to how we search for gravitational-wave signals. Following the identification of the best fitting template for each scattered light glitch in the data, we can clean the gravitational-wave data by subtracting them. Cleaning gravitational-wave data can uncover previously obscured gravitational-wave events and will ultimately improve the sensitivity of the detectors.
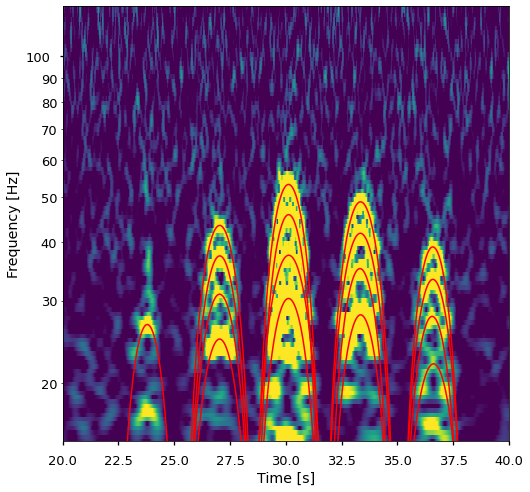
A random forest classifier to distinguish between chirps and glitches – Neev Shah (UBC)
Glitches can often hinder the search for gravitational waves by showing up as false candidates. We develop a new statistical distinguisher that can distinguish between different types of glitches and chirps. Assuming all events as real signals (glitches are not!), we project them onto a gravitational-wave model to infer the (posterior) probability distributions of their astrophysical parameters. We extract particular features from these posterior distributions and use a tool called Random Forests for the purpose of classification. Random forests can identify spatial clusterings in the parameter space that can help separate different classes of glitches and gravitational waves.
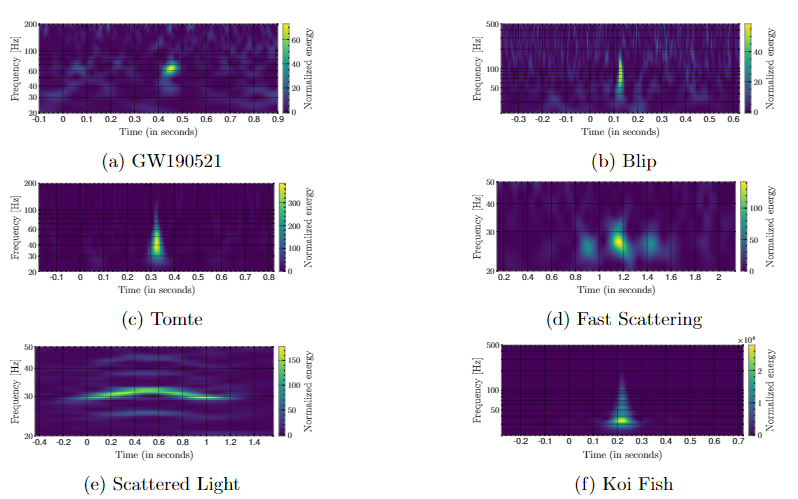
We find that for specific astrophysical parameters like the mass and spins of the binaries, the posteriors for glitches are starkly different from those of simulated gravitational waves, and the random forest can identify them to separate different glitch families and gravitational waves. We train our model using hundreds of simulated gravitational waves and thousands of glitches from 5 glitch families (Blips, Tomtes, Koi Fish, Fast Scattering and Scattered Light) that were pre-classified by Gravity Spy! We find that our method can be quite useful for the purpose of classification as it has an overall accuracy of about 97% and a Chirp recall of about 90%. This tool might help in future observing runs when there would be a lot of candidate events, and a large number of glitches among them.
GSpyNetTree: Improving Gravity Spy classifications toward O4 – Sofía Álvarez-López (UBC)
When detecting gravitational waves, removing glitches is one of our most significant challenges. Gravity Spy has helped us classify many of these glitches, proving very helpful for LIGO detector characterization. However, as one of LIGO’s core missions is the detection of gravitational waves, it is worth focusing on their search. In this sense, we discovered that Gravity Spy has the potential to be more than a glitch classifier: a gravitational wave vs glitch classifier!
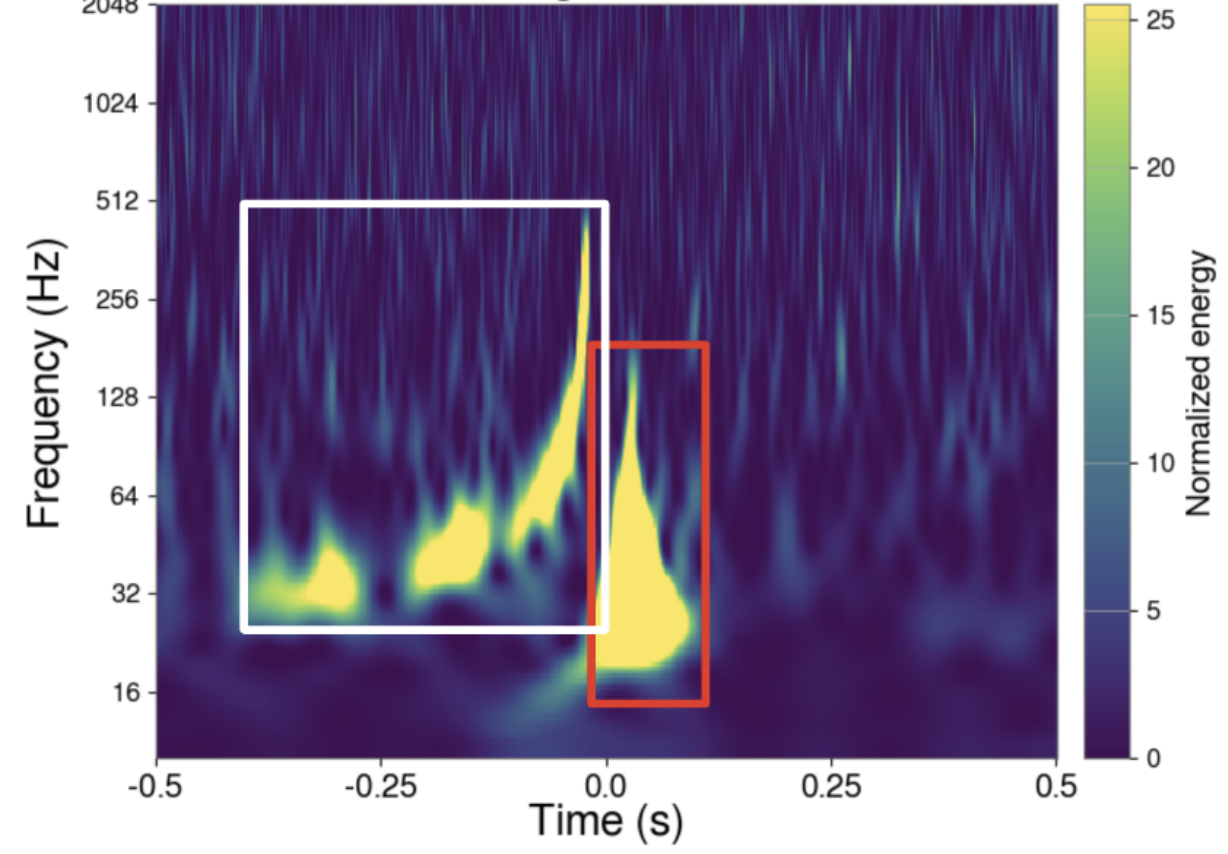
Nevertheless, we had to restructure Gravity Spy to do so. Moreover, in the context of the 4th LIGO–Virgo–KAGRA observing run, new challenges arise in gravitational-wave classification, as detectors are expected to be more sensitive. The possible appearance of new glitches, and the likely occurrence of overlapping glitches and GWs (as shown in the image above), suggest the need for a new model for GW classification. We studied how Gravity Spy responded to these challenges and developed GSpyNetTree, the Gravity Spy Convolutional Neural Network Decision Tree: a gravitational wave vs glitch classifier that aims to tackle these challenges.
Towards unified modelling of astrophysical and background populations – Jack Heinzel (MIT)
One of the challenges of LIGO analysis is identifying which signals are astrophysical in origin and which signals are environmental noise. Recent progress has been made in identifying common signatures of Gravity Spy-identified environmental noise, which are unlikely to occur for real astrophysical gravitational waves.
In particular, when environmental noise is analyzed as a coalescence of a compact binary, the (nonphysical) parameters corresponding to the signal are so different from parameters we usually observe in astrophysical signals that we can confidently separate the noise population from the astrophysical population. We can then analyze the properties of events which are more ambiguous in origin, simultaneously estimating the probability of astrophysical vs terrestrial origin. The astrophysical information is then folded in to constrain the population of astrophysical events.
That’s all from us. Once again, a big thanks for all the classifying you’ve all done so far: as you can see, we’re chipping away at the glitch problem but there’s still plenty of work to be done!
- Christian Chapman-Bird, on behalf of the Gravity Spy team.
